
介绍
ZooKeeper 是一个开源的分布式协调服务,为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册
ZooKeeper致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务
使用 Java 开发
- 高性能:将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,尤其是
已读为主的应用场景 - 高可用:以集群的方式对外提供服务,只要集群中超过一半的机器都能够正常工作,Name 整个集群就能正常对外服务
- 严格的访问顺序:对于来自客户端的每个事务请求,
zk都会分配一个全局事务 id:zxid,用以控制所有事务操作的先后顺序
zk 集群角色
- Leader:集群工作的核心,事务请求的唯一调度和处理者;对于有写操作的请求,需统一转发给
Leader处理,Leader 需决定编号执行操作 - Follower:处理客户端非事务请求,转发事务请求给 Leader,参与 Leader 选举
- Observer:处理非事务请求的独立处理,对于事务请求,同样转发给 Leader 服务器进行处理,不参与 leader 的选举,不参与
2PC数据的同步过程
zk 的权限控制
zk 的 ACL(Access Control List) 即访问控制列表,权限在生产环境中还是很重要的一环
zk 的 acl 通过 [scheme:id:permissions] 来定义权限列表
- scheme
- :代表采用的某种权限机制,包括 world、auth、digest、ip 这几种。
- world
- :默认方式,相当于全世界都能访问
- auth
- :代表已经认证通过的用户
- digest
- :使用用户名和密码的方式进行认证
- ip
- :使用 ip 地址的方式进行认证,可以指定具体的 ip 或者地址段
- id:代表允许访问的用户。
- permissions:权限组合字符串,由 cdrwa 组成,其中每个字母代表支持不同权限,创建权限 create(c)、删除权限 delete(d)、读权限 read(r)、写权限 write(w)、管理权限 admin(a),管理员权限是允许进行 ACL 的操作,其中 d 是对子节点的操作权限,其他的都是对自身节点的操作权限
使用 digest 模式进行权限控制
编写工具类生成创建 digest 模式用户所需要的用户名和密码
导入 maven 依赖
<!-- 创建 Zookeeper 客户端依赖,一定要和 Zookeeper Server 版本保持一致 curator依赖中其实也包含,但是这边为了版本
对应显示的声明了一下-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
<exclusions>
<!--因为 zk 包使用的是 log4j 日志,和 springboot 的logback 日志冲突 -->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>编写工具类
package com.aha.utils;
import lombok.extern.slf4j.Slf4j;
import org.I0Itec.zkclient.ZkClient;
import org.apache.zookeeper.server.auth.DigestAuthenticationProvider;
import java.security.NoSuchAlgorithmException;
/**
* zk 的工具类
*
* @author: WT
* @date: 2021/12/1 16:36
*/
@Slf4j
public class ZkUtils {
/**
* 生成 digest 用户名和密码的加密串
* @param idPassword 用户名和密码的明文
* @return
* @throws NoSuchAlgorithmException
*/
public static String getDigestAuthStr (String idPassword) throws NoSuchAlgorithmException {
return DigestAuthenticationProvider.generateDigest(idPassword);
}
public static void main(String[] args) throws NoSuchAlgorithmException {
// user:svY1VPBeOtL797NihAvQMUtFLHs=
log.info(ZkUtils.getDigestAuthStr("user:111111"));
}
}根据生成的加密权限串对相应的节点进行设置
`# 创建 aha 节点,并设置 user:111111 用户拥有 读写和删除权限和设置acl权限 $ create /aha aha-data digest:user:svY1VPBeOtL797NihAvQMUtFLHs=:rwda # 执行命令之后在不进行用户登录时在查看 /aha 节点 $ ls /aha # 返回权限不足 [zk: localhost:2181(CONNECTED) 2] get /aha Insufficient permission : /aha # 进行用户的登陆 然后在查看相应的节点 $ addauth digest user:111111 $ get /aha # 就可以正常的进行查看了 [zk: localhost:2181(CONNECTED) 7] get /aha aha-data`zk 的读写机制
zk 使用单一的主进程 Leader 来接收和处理客户端所有事务请求,注意这里是事务请求,非事务请求可以直接通过 follower 或 observer 进行操作。
所谓事务请求便是涉及到数据修改的请求:新增,修改,删除
所谓非事务请求便是:查询操作
当非 leader 节点接受到了事务操作,它会将请求转发给 leader 节点来处理。
zk 的数据同步流程
在 zk 中主要依赖 ZAB:(Zookeeper Atomic Broadcas) 原子消息广播协议来实现分布式数据的一致性。
ZAB 协议与 Paxos 类似,也是一种数据一致性的算法,他主要包括:消息广播 和 崩溃恢复 两个部分。
消息广播
当节点收到客户端或者 observer,follower 节点转发过来的事务请求后,leader 节点会将此请求转化为 Proposal: (提议) 广播到所有的 follower 节点,
注意这边不包括 observer 节点,当集群中有过半的 follower 节点给 leader 节点进行了正确的 ACK 反馈,这时候 leader 节点就会像所有的 follower 节点发送 commit 消息,将此次提议进行提交。
这个过程可以被称为 2PC 事务提交。如下图所示: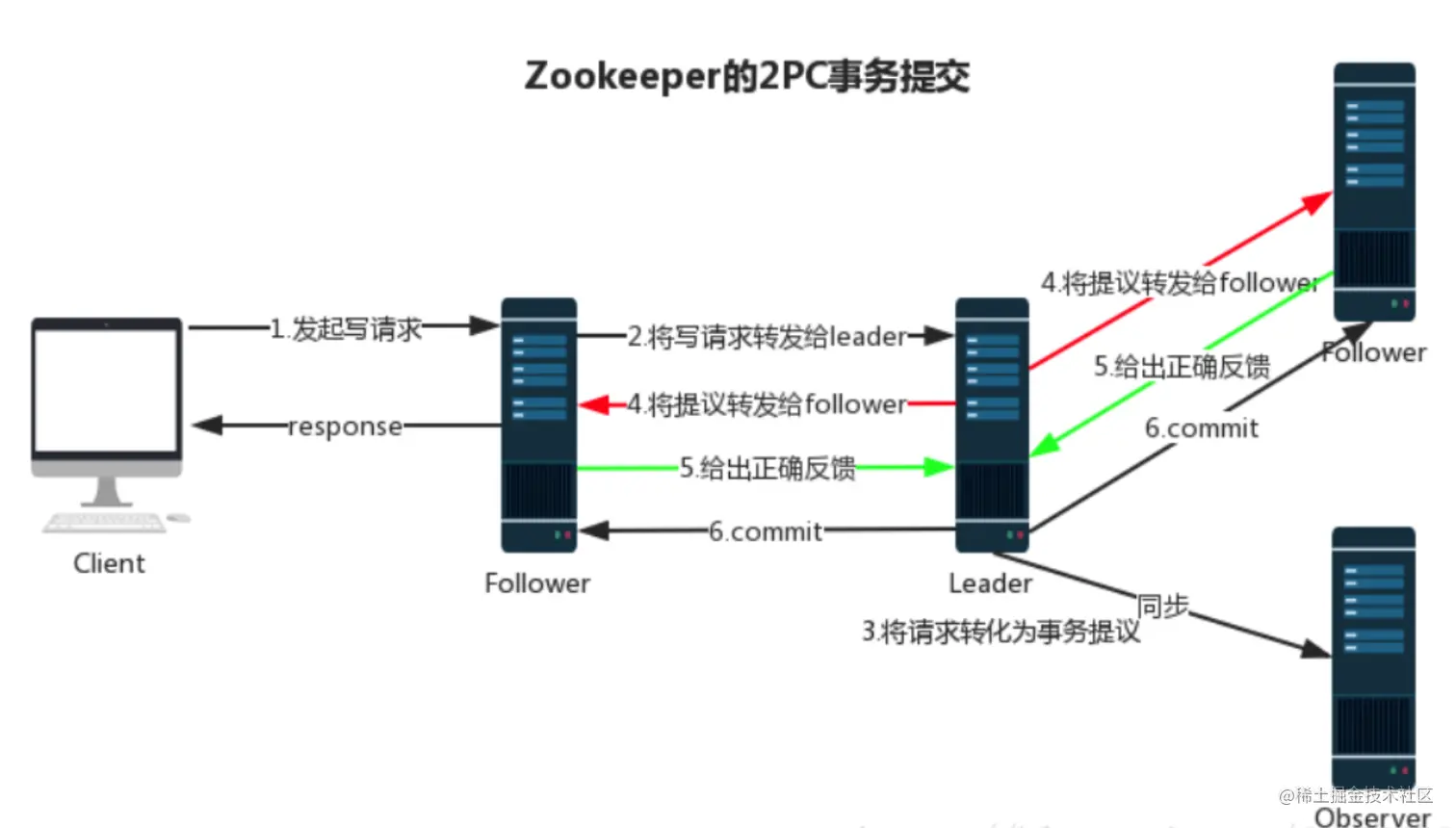
注意:
observer节点只负责同步leader的数据,全程不参与2PC的过程。ACK : Acknowledge character确认字符
崩溃恢复
在正常情况消息广播情况下能运行良好,但是一旦 Leader 服务器出现崩溃,或者由于网络原理导致 Leader 服务器失去了与过半 Follower 的通信,那么就会进入崩溃恢复模式,需要选举出一个新的 Leader 服务器
在这个过程中可能会出现两种数据不一致性的隐患,需要 ZAB 协议的特性进行避免
ZAB 协议的恢复模式使用了以下策略:
- 选举
zxid最大的节点作为新的leader - 新
leader将事务日志中尚未提交的消息进行处理
zk 的不足
zk的性能有限,tps大概只能达到一万多,因为只有leader节点可以处理事务请求。zk选取主节点的时候是没有办法对外服务的,而且这个过程也相对较慢。zk的权限控制相对较简单。zk进行读取的时候可能读取的是旧数据。因为zk的过半原则,当有一半以上的机器数据同步完成就认为是数据同步完成了,你读取的那个节点可能就是没有同步的那个节点
参考
贡献者
 jiechen
jiechen