JavaScript 引擎
我们写的 JavaScript 代码直接交给浏览器或者 Node 执行时,底层的 CPU 是不认识的,也没法执行。CPU 只认识自己的指令集,指令集对应的是汇编代码。写汇编代码是一件很痛苦的事情,比如,我们要计算 N 阶乘的话,只需要 7 行的递归函数:
function factorial(N) {
if (N === 1) {
return 1;
} else {
return N * factorial(N - 1);
}
}代码逻辑也非常清晰,与阶乘的数学定义完美吻合,哪怕不会写代码的人也能看懂。
但是,如果使用汇编语言来写 N 阶乘的话,要 300+ 行代码 n-factorial.s:
它需要处理 10 进制与 2 进制的转换,需要使用多个字节保存大整数,最多可以计算大概 500 左右的 N 阶乘。
还有一点,不同类型的 CPU 的指令集是不一样的,那就意味着得给每一种 CPU 重写汇编代码,这就很崩溃了。。。
还好,JavaScirpt 引擎可以将 JS 代码编译为不同 CPU(Intel, ARM 以及 MIPS 等) 对应的 汇编代码,这样我们才不要去翻阅每个 CPU 的指令集手册。当然,JavaScript 引擎的工作也不只是编译代码,它还要负责执行代码、分配内存以及 垃圾回收。
虽然浏览器非常多,但是主流的 JavaScirpt 引擎其实很少,毕竟开发一个 JavaScript 引擎是一件非常复杂的事情。比较出名的 JS 引擎有这些:
- V8 (Google)
- SpiderMonkey (Mozilla)
- JavaScriptCore (Apple)
- Chakra (Microsoft)
- IOT:duktape、JerryScript
还有,最近发布 QuickJS 与 Hermes 也是 JS 引擎,它们都超越了浏览器范畴,Atwood’s Law 再次得到了证明:
Any application that can be written in JavaScript, will eventually be written in JavaScript.
V8 引擎
在为数不多 JavaScript 引擎中,V8 无疑是最流行的,Chrome 与 Node.js 都使用了 V8 引擎,Chrome 的市场占有率高达 60%,而 Node.js 是 JS 后端编程的事实标准。国内的众多浏览器,其实都是基于 Chromium 浏览器开发,而 Chromium 相当于开源版本的 Chrome,自然也是基于 V8 引擎的。神奇的是,就连浏览器界的独树一帜的 Microsoft 也投靠了 Chromium 阵营。另外,Electron 是基于 Node.js 与 Chromium 开发桌面应用,也是基于 V8 的
内部结构
V8 是一个非常复杂的项目,使用 cloc 统计可知,它竟然有超过 100 万行 C++ 代码。
V8 由许多子模块构成,其中这 4 个模块是最重要的:
- Parser:将 JavaScript 源码转换为 Abstract Syntax Tree (AST);
- Ignition:解释器,将 AST 转换为 Bytecode,解释并执行 Bytecode;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型;
- TurboFan:编译器,利用 Ignitio 所收集的类型信息,将 Bytecode 转换为优化的汇编代码(计算机可识别);
- Orinoco:垃圾回收,负责将程序不再需要的内存空间回收。
转换过程
其中,Parser,Ignition 以及 TurboFan 可以将 JS 源码编译为汇编代码,其流程图如下:
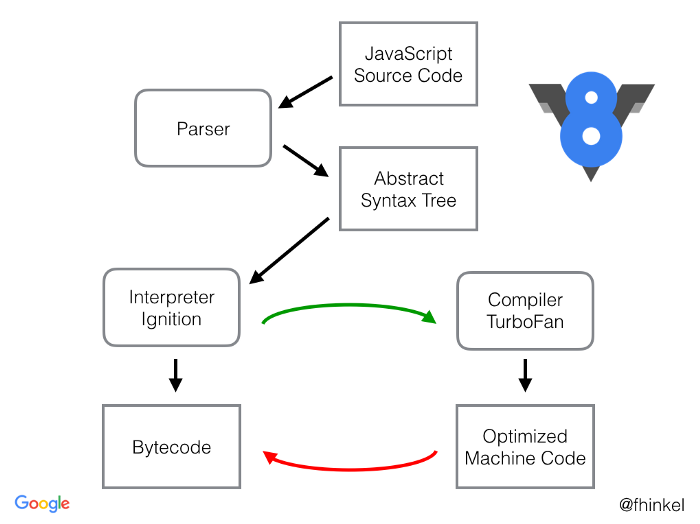
简单地说,Parser 将 JS 源码转换为 AST,然后 Ignition 将 AST 转换为 Bytecode,最后 TurboFan 将 Bytecode 转换为经过优化的 Machine Code(实际上是汇编代码)。
- 如果函数没有被调用,则 V8 不会去编译它。
- 如果函数只被调用 1 次,则 Ignition 将其编译 Bytecode 就直接解释执行了。TurboFan 不会进行优化编译,因为它需要 Ignition 收集函数执行时的类型信息。这就要求函数至少需要执行 1 次,TurboFan 才有可能进行优化编译。
- 如果函数被调用多次,则它有可能会被识别为热点函数,且 Ignition 收集的类型信息证明可以进行优化编译的话,这时 TurboFan 则会将 Bytecode 编译为 Optimized Machine Code,以提高代码的执行性能。
图片中的红线是逆向的,这的确有点奇怪,Optimized Machine Code 会被还原为 Bytecode,这个过程叫做 Deoptimization。这是因为 Ignition 收集的信息可能是错误的,比如 add 函数的参数之前是整数,后来又变成了字符串。生成的 Optimized Machine Code 已经假定 add 函数的参数是整数,那当然是错误的,于是需要进行 Deoptimization。
function add(x, y) {
return x + y;
}
add(1, 2);
add("1", "2");在运行 C、C++ 以及 Java 等程序之前,需要进行编译,不能直接执行源码;但对于 JavaScript 来说,我们可以直接执行源码 (比如:node server.js),它是在运行的时候先编译再执行,这种方式被称为即时编译 (Just-in-time compilation),简称为 JIT。因此,V8 也属于 JIT 编译器。
Ignition: 解释器
在 V8 出现之前,所有的 JavaScript 虚拟机所采用的都是解释器来解释执行的方式,这是 JavaScript 执行速度过慢的主要原因之一。
解释器的工作方式: 边解释,边执行。 解析器解析代码,生成对应字节码,然后解释器直接解释执行字节码。这样子虽然启动快,但对于循环等会存在解释多次的情况。从而导致运行速度变慢,影响到 js 的执行效率。
for (let i = 0; i < len; i++) {
doSomething(i)
}如何看到解释器生成的 Bytecode: Node.js 是基于 V8 引擎实现的,因此 node 命令提供了很多 V8 引擎的选项,使用 node 的 --print-bytecode 选项,可以打印出 Ignition 生成的 Bytecode。
factorial.js 如下,由于 V8 不会编译没有被调用的函数,因此需要在最后一行调用 factorial 函数。
function factorial(N) {
if (N === 1) {
return 1;
} else {
return N * factorial(N - 1);
}
}
factorial(10);使用 node 命令 (node 版本为 12.6.0) 的 --print-bytecode 选项,打印出 Ignition 生成的 Bytecode:
node --print-bytecode factorial.js然后就可以看到 bytecode 结果了
TurboFan: 编译器
这留到下一章讲解
JIT
JIT 是什么
为了解决 解释器 的低效问题,V8 把 编译器 也引入进来,结合了解释器和编译器两者优点设计了即时编译(JIT)的双轮驱动的设计,形成混合模式,给 JavaScript 的执行速度带来了极大的提升。
JIT,全称是 Just In Time,混合使用编译器和解释器的技术。
- 编译器启动速度慢,执行速度快
- 解释器的启动速度快,执行速度慢(之前的 JS 虚拟机采用方式)
绝大多数编译器以预先编译(AOT)或实时编译(JIT)形式工作。
- 使用命令行或者集成开发环境(IDE)调用预先编译(AOT)的编译器,如 gcc
- 实时编译器通常是用来提高性能的,令你没有感知的,如 V8
实现思想
在 JavaScript 引擎中增加一个监视器(也叫分析器)。在 解释器 解释字节码的时候增加一个监视器(monitor),记录代码一共运行了多少次、如何运行的等信息。
如果发现一段代码会被重复执行,则监视器会将此段代码标记为热点代码,同时交给 V8 提供的 编译器 对这段字节码进行编译,编译为二进制代码,然后再对编译后的二进制代码执行优化操作,从而提供其执行效率。
等后面 V8 再次执行这段代码,则会跳过解释器,采用这段优化后的代码进行编译执行,从而提升代码的运行效率。
编译器优化过程
factorial.js 如下,由于 V8 不会编译没有被调用的函数,因此需要在最后一行调用 factorial 函数。
function factorial(N) {
if (N === 1) {
return 1;
} else {
return N * factorial(N - 1);
}
}
factorial(10); // V8不会编译没有被调用的函数,因此这一行不能省略字节码
使用 node 命令 (node 版本为 12.6.0) 的 --print-bytecode 选项,打印出 Ignition 生成的 Bytecode:
node --print-bytecode factorial.js控制台输出的内容非常多,最后一部分是 factorial 函数的 Bytecode
生成的 Bytecode:
- 使用 LdaSmi 命令将整数 1 保存到寄存器;
- 使用 TestEqualStrict 命令比较参数 a0 与 1 的大小;
- 如果 a0 与 1 相等,则 JumpIfFalse 命令不会跳转,继续执行下一行代码;
- 如果 a0 与 1 不相等,则 JumpIfFalse 命令会跳转到内存地址 0x3541c2da1139
优化后的汇编代码
使用 node 命令的 --print-code 以及 --print-opt-code 选项,打印出 TurboFan 生成的汇编代码:
node --print-code --print-opt-code factorial.js
示例
我们先不管这些汇编代码,通过 add 函数来看看编译器具体是如何运作的
function add(x, y) {
return x + y;
}
add(1, 2);
add(3, 4);
add(5, 6);
add("7", "8");由于 JS 的变量是没有类型的,所以 add 函数的参数可以是任意类型:Number、String、Boolean 等,如果直接编译的话,生成的汇编代码比如会有很多 if…else 分支,伪代码如下:
if (isInteger(x) && isInteger(y)) {
// 整数相加
} else if (isFloat(x) && isFloat(y)) {
// 浮点数相加
} else if (isString(x) && isString(y)) {
// 字符串拼接
} else {
// 各种其他情况,很长
}Ignition 在执行 add(1, 2) 时,已经知道 add 函数的两个参数都是整数,那么 TurboFan 在编译 Bytecode 时,就可以假定 add 函数的参数是整数,这样可以极大地简化生成的汇编代码,伪代码如下:
if (isInteger(x) && isInteger(y)) {
// 整数相加
} else {
// Deoptimization
}接下来的 add(3, 4) 与 add(3, 4) 可以执行优化的汇编代码,但是 add("7", "8") 只能 Deoptimize 为 Bytecode 来执行。 当然,TurboFan 所做的也不只是根据类型信息来简化代码执行流程,它还会进行其他优化,比如减少冗余代码等更复杂的事情。
我们可以看出,如果我们的 JS 代码中变量的类型变来变去,是会给 V8 引擎增加不少麻烦的,为了提高性能,我们可以尽量不要去改变变量的类型,少使用 delete 等操作,同时推荐使用 typescript 这种静态语言支持的语言进行编码。
JIT 弊端
JIT 混合了编译器,必然会多一些开销
- 优化和去优化开销
- 监视器记录信息对内存的开销
- 发生去优化情况时恢复信息的记录对内存的开销
- 对基线版本和优化后版本记录的内存开销
所以,整体来看是一个空间换时间的优化方案。
Q & A
AST 存在的意义
相比于源代码的语法结构,将其抽象为一个 AST 更有助于开发者去分析其语法结构和特性,在 AST 的解析过程中我们可以把一颗初始化的 ast,根据预期的结构样式进行 transform,从而得到一颗理想化的 ast
ast 的构建周期
归纳起来可以把 AST 的使用操作分为以下几个步骤:
解析 (Parsing):这个过程由编译器实现,会经过词法分析过程和语法分析过程,从而生成
AST。读取/遍历 (Traverse):深度优先遍历
AST,访问树上各个节点的信息(Node)。修改/转换 (Transform):在遍历的过程中可对节点信息进行修改,生成新的
AST。输出 (Printing):对初始
AST进行转换后,根据不同的场景,既可以直接输出新的AST,也可以转译成新的代码块。
通常情况下使用 AST,重点关注步骤 2 和 3,诸如 Babel、ESLint 等工具暴露出来的通用能力都是对初始 AST 进行访问和修改
访问者模式
这两步的实现基于一种名为访问者模式的设计模式,即定义一个 visitor 对象,在该对象上定义了对各种类型节点的访问方法,这样就可以针对不同的节点做出不同的处理。例如,编写 Babel 插件其实就是在构造一个 visitor 实例来处理各个节点信息,从而生成想要的结果。
访问者模式详情参考:认识Babel的Visitor——访问者模式 - 掘金
字节码存在的意义
直接从高级语言处理得到机器语言,需要解释器(编译器)去兼顾不同 cpu 的不同指令集,导致对应模块工程量复杂化
有了字节码之后:
- 解释器兼容不同 CPU 的架构
- 从原始的高级语言编译得到机器语言会更快(原先每次编译都需要从 1-2-3,字节码的存在可以复用 1-2 这一流程的产物
参考
JavaScript深入浅出第4课:V8引擎是如何工作的? | 寒雁Talk
贡献者
 jiechen
jiechen